Redis数据结构
数据类型
5种基本类型
5 种常见的基本类型有:String、List、Set、Zset、Hash
| 类型 | 存储的值 | 读写能力 |
|---|---|---|
| String | 字符串、整数或浮点数 | 对整个字符串或字符串的一部分进行操作;对整数或者浮点数进行自增或自减操作 |
| List | 链表,链表每个节点都是一个字符串 | 对链表的两端进行push和pop操作,读取单个或者多个元素;根据值查找或删除元素 |
| Set | 字符串的无序集合 | 字符串的集合,基础操作有添加、删除、获取;同时还有计算交集、并集、差集等 |
| Hash | 包含键值对的无序散列表 | 基本方法有添加、获取、删除单个元素方法 |
| Zset | 与Hash相同,用于存储键值对 | 字符串成员与浮点数之间的有序映射,元素的排列顺序由分数的大小决定;基本方法有添加、获取、删除单个元素以及根据分数范围或成员来获取元素 |
String
String是redis中最基本的数据类型,一个key对应一个value。
String类型是二进制安全的,意思是 redis 的 string 可以包含任何数据。如数字,字符串,jpg图片或者序列化的对象。
String类型的常用操作有:
| 命令 | 简述 | 使用 |
|---|---|---|
| GET | 获取存储在给定键中的值 | GET name |
| SET | 设置存储在给定键中的值 | SET name value |
| DEL | 删除存储在给定键中的值 | DEL name |
| INCR | 将键存储的值加1 | INCR key |
| DECR | 将键存储的值减1 | DECR key |
| INCRBY | 将键存储的值加上整数 | INCRBY key amount |
| DECRBY | 将键存储的值减去整数 | DECRBY key amount |
更加详细的string操作参考:https://www.redis.net.cn/order/3544.html
string的常用场景:
- 缓存:把常用信息,字符串,图片或者视频等信息放到redis中,redis作为缓存层,mysql做持久化层,降低mysql的读写压力
- 计数器:redis是单线程模型,一个命令执行完才会执行下一个,同时数据可以一步落地到其他的数据源。
- session:常见方案spring session + redis实现session共享,
List
List是redis中的链表,在redis中是使用双端链表实现的。
使用List结构,我们可以轻松地实现最新消息排队功能(比如新浪微博的TimeLine)。
List的另一个应用就是消息队列,可以利用List的 PUSH 操作,将任务存放在List中,然后工作线程再用 POP 操作将任务取出进行执行。
List类型的常用操作有:
| 命令 | 简述 | 使用 |
|---|---|---|
| RPUSH | 将给定值推入到列表右端 | RPUSH key value |
| LPUSH | 将给定值推入到列表左端 | LPUSH key value |
| RPOP | 从列表的右端弹出一个值,并返回被弹出的值 | RPOP key |
| LPOP | 从列表的左端弹出一个值,并返回被弹出的值 | LPOP key |
| LRANGE | 获取列表在给定范围上的所有值 | LRANGE key 0 -1 |
| LINDEX | 通过索引获取列表中的元素。你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。 | LINDEX key index |
| LTRIM | 让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除 | LTRIM KEY_NAME START STOP |
| BRPOP | 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 | BRPOP LIST1 LIST2 .. LISTN TIMEOUT |
更加详细的list操作参考:https://www.redis.net.cn/order/3577.html
使用技巧:
- 作为桟使用:lpush + lpop
- 作为队列使用:lpush + rpop
- 作为有限集合使用:lpush + ltrim
- 作为消息队列使用:lpoush + brpop
list的常用场景:
- 微博TimeLine: 有人发布微博,用lpush加入时间轴,展示新的列表信息。
- 消息队列
Set
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
Set类型的常用操作有:
| 命令 | 简述 | 使用 |
|---|---|---|
| SADD | 向集合添加一个或多个成员 | SADD key value |
| SCARD | 获取集合的成员数 | SCARD key |
| SMEMBERS | 返回集合中的所有成员 | SMEMBERS key member |
| SISMEMBER | 判断 member 元素是否是集合 key 的成员 | SISMEMBER key member |
更加详细的set操作参考:https://www.redis.net.cn/order/3594.html
set的常用场景:
- 标签(tag),给用户添加标签,或者用户给消息添加标签,这样有同一标签或者类似标签的可以给推荐关注的事或者关注的人。
- 点赞,或点踩,收藏等,可以放到set中实现
Hash
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
hash类型的常用操作有:
| 命令 | 简述 | 使用 |
|---|---|---|
| HSET | 添加键值对 | HSET hash-key sub-key1 value1 |
| HGET | 获取指定散列键的值 | HGET hash-key key1 |
| HGETALL | 获取散列中包含的所有键值对 | HGETALL hash-key |
| HDEL | 如果给定键存在于散列中,那么就移除这个键 | HDEL hash-key sub-key1 |
hash 主要是和维护对象信息,使缓存数据更加直观,同时也不string更节省空间。
更加详细的hash操作参考:https://www.redis.net.cn/order/3564.html
Zset
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的, 但分数(score)却可以重复。有序集合是通过两种数据结构实现:
- 压缩列表(ziplist):为了提高存储效率而设计的一种特殊编码的双向链表。它可以存储字符串或者整数,存储整数时是采用整数的二进制而不是字符串形式存储。它能在O(1)的时间复杂度下完成list两端的push和pop操作。但是因为每次操作都需要重新分配ziplist的内存,所以实际复杂度和ziplist的内存使用量相关。详细说明
- 跳跃表(zSkiplist):跳跃表的性能可以保证在查找,删除,添加等操作的时候在对数期望时间内完成,这个性能是可以和平衡树来相比较的,而且在实现方面比平衡树要优雅,这是采用跳跃表的主要原因。跳跃表的复杂度是O(log(n))。详细说明
zset类型的常用操作有:
| 命令 | 简述 | 使用 |
|---|---|---|
| ZADD | 将一个带有给定分值的成员添加到有序集合里面 | ZADD zset-key 178 member1 |
| ZRANGE | 根据元素在有序集合中所处的位置,从有序集合中获取多个元素 | ZRANGE zset-key 0-1 withccores |
| ZREM | 如果给定元素成员存在于有序集合中,那么就移除这个元素 | ZREM zset-key member1 |
更加详细的zset操作参考:https://www.redis.net.cn/order/3609.html
3种特殊类型
redis的三种特殊的数据类型,分别是 HyperLogLogs(基数统计), Bitmaps (位图) 和 geospatial (地理位置)。
HyperLogLogs(基数统计)
在redis 2.8.9 版本新增了HyperLogLogs数据结构
HyperLogLogs可以非常省内存的去做统计计数,比如注册 IP 数、每日访问 IP 数、页面实时 UC、在线用户数,共同好友数等。
例如要对于一个网站的访问数进行统计,假如每天访问的 IP 有 100 万,一个 IP 消耗 15 字节,那么 100 万个 IP 就是 15M。而使用HyperLogLogs 在redis中每个键咱用的内容都是 12K,理论上存储近视 2^64 个值,不管存储的内容是什么,它基于基数估算的算法,可以使用少量固定的内存去识别集合中的唯一元素。
需要注意的是,这个估算并不是完全准确的,它拥有0.81%的误差,当然对于一些允许容错的业务场景,这个误差是可以忽略不计的。
HyperLogLogs类型的常用操作有:
| 命令 | 简述 | 使用 |
|---|---|---|
| PFMERGE | 将多个 HyperLogLog 合并为一个 HyperLogLog ,合并后的 HyperLogLog 的基数估算值是通过对所有 给定 HyperLogLog 进行并集计算得出的。 | PFMERGE destkey sourcekey [sourcekey …] |
| PFADD | 将所有元素参数添加到 HyperLogLog 数据结构中 | PFADD key element [element …] |
| PFCOUNT | 返回给定 HyperLogLog 的基数估算值 | PFCOUNT key [key …] |
Bitmaps (位图)
Bitmap 即位图数据结构,都是操作二进制位来进行记录,只有0 和 1 两个状态。
常用来存储统计信息,例如统计用户的登录状态、考勤系统记录员工的打卡状态等。
bitmap类型的常用操作有:
| 命令 | 简述 | 使用 |
|---|---|---|
| setbit | 设置值 | setbit key num 1/0 |
| getbit | 获取值 | getbit key num |
| bitcount | 位统计,获取值为 1 的个数 | bitcount key |
geospatial(地理位置)
Redis 的 Geo 在 Redis 3.2 版本就推出了! 这个功能可以推算地理位置的信息: 两地之间的距离, 方圆几里的人
geospatial类型的常用操作有:
| 命令 | 简述 | 使用 |
|---|---|---|
| GEOHASH | 返回一个或多个位置的hash值,如果字符串越接近则距离越近 | GEOHASH Sicily Palermo Catania |
| GEOPOS | 从key里返回所有给定位置元素的位置(经度和纬度) | GEOPOS Sicily Palermo Catania NonExisting |
| GEODIST | 返回两个给定位置之间的距离 | GEODIST Sicily Palermo Catania [km/mi] |
| GEORADIUS | 以给定的经纬度为中心,找出某一半径内的元素 | GEORADIUS Sicily 15 37 200 km WITHCOORD |
| GEOADD | 将指定的地理空间位置(纬度、经度、名称)添加到指定的key中 | GEOADD Sicily 13.361389 38.115556 “Palermo” |
| GEORADIUSBYMEMBER | 指定成员的位置被用作查询的中心,找出位于指定范围内的元素 | GEORADIUSBYMEMBER Sicily Agrigento 100 km |
stream类型
stream类型是在redis5.0中新增的,它借鉴了kafka的设计,是redis一个新的、强大的支持多播的可持久化的消息队列。
在 redis5.0 之前,基于redis实现消息队列的方法都存在一些弊端,比如:
- PUB/SUB 发布订阅模式,无法持久化,如果出现网络问题、redis服务宕机问题,消息则会丢失
- List LPUSH + BRPOP 或者 Sorted-Set 的实现,虽然支持了持久化,但是不支持多播、分组消费等
在redis新增stream类型后,基于此类型实现消息队列,虽然并不能实现一个完全体的消息队列,但也能做到一个轻量级的实践,可以满足的需求有:
- 消息持久化
- 消息的基本增删改查操作
- 单播、多播、组播
- 监控消息状态
常用命令
stream类型的常用操作有:
| 命令 | 简述 | 使用 |
|---|---|---|
| XADD | 添加消息到末尾 | XADD key ID field string [field string …] |
| XGROUP | 管理流数据结构关联的消费者组 | XGROUP CREATE mystream consumer-group-name |
| XTRIM | 对消息进行修剪,限制长度 | XTRIM key MAXLEN [~] count |
| XDEL | 删除消息 | XDEL key ID [ID …] |
| XLEN | 获取消息长度 | xlen key |
| XRANGE | 获取消息列表,自动过滤已经删除的消息 | XRANGE key start end [COUNT count] |
| XREVRANGE | 反向获取消息列表 | XREVRANGE key end start [COUNT count] |
| XREAD | 以阻塞或非阻塞方式获取消息列表 | XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key …] ID [ID …] |
使用range命令时,可以用 - 表示最小值,用 + 表示最大值
XGROUP的作用主要有:
- 创建与流关联的新消费者组。
- 销毁一个消费者组。
- 从消费者组中移除指定的消费者。
- 将消费者组的最后交付ID设置为其他内容。
更加消息的命令说明参考:http://www.redis.cn/commands/xadd.html
结构组成
对于 stream 类型,每个 stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建。
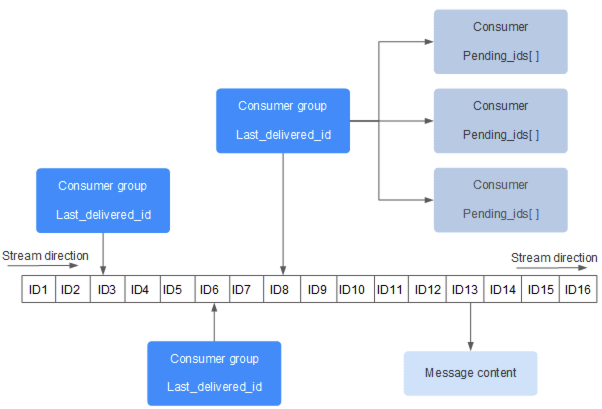
如图所示,可以清晰的看见,当我们使用stream类型构建消息队列,主要有 3 个要点:
- consumer group:消费组,使用
XGROUP CREATE命令创建,一个消费组有多个消费者(Consumer),这些消费者彼此之间属于竞争关系 - last_delivered_id:游标,每个消费组会有一个游标last_delivered_id,任意一个消费者读取了消息都会使游标last_delivered_id往前移动
- pending_ids:消费者的状态变量,作用是维护消费者的未确认的id,记录当前已经被客户端读取的消息,但还没有ack(被确认的标记)
另外,在使用stream结构构建消息队列时,还需要注意:
- 消息 ID:消息 ID 的形式是timestampInMillis-sequence,例如1527846880572-5,它表示当前的消息在毫米时间戳1527846880572时产生,并且是该毫秒内产生的第5条消息。消息ID可以由服务器自动生成,也可以由客户端自己指定,但是形式必须是整数-整数,而且必须是后面加入的消息的ID要大于前面的消息ID。
- 消息内容:消息内容就是键值对,比如hash结构的键值对。
独立消费
上面提到的均为针对消费组的情况下进行消费,而strem类型也支持独立消费,redis提供了单独的消费指令 —— XREAD。
使用xread时,我们可以完全忽略消费组(Consumer Group)的存在,就好比Stream就是一个普通的列表(list)。
使用xread时,客户端如果想要使用xread进行顺序消费,一定要记住当前消费到哪里了,也就是返回的消息ID。下次继续调用xread时,将上次返回的最后一个消息ID作为参数传递进去,就可以继续消费后续的消息。
xread的参数,block 0表示永远阻塞,直到消息到来,block 1000表示阻塞1s,如果1s内没有任何消息到来,就返回nil,使用示例:
- 从Stream头部读取两条消息:xread count 2 streams codehole 0-0
- 从Stream尾部读取一条消息,毫无疑问,这里不会返回任何消息:xread count 1 streams codehole $
- 从尾部阻塞等待新消息到来,下面的指令会堵住,直到新消息到来:xread block 0 count 1 streams codehole $
- 我们从新打开一个窗口,在这个窗口往Stream里塞消息:xadd codehole * name youming age 60
消费组消费
消费组相关的命令:
- XGROUP CREATE - 创建消费者组
- XREADGROUP GROUP - 读取消费者组中的消息
- XACK - 将消息标记为”已处理”
- XGROUP SETID - 为消费者组设置新的最后递送消息ID
- XGROUP DELCONSUMER - 删除消费者
- XGROUP DESTROY - 删除消费者组
- XPENDING - 显示待处理消息的相关信息
- XCLAIM - 转移消息的归属权
- XINFO - 查看流和消费者组的相关信息;
- XINFO GROUPS - 打印消费者组的信息;
- XINFO STREAM - 打印流信息
信息监控
使用 XINFO 命令可以对stream进行监控:
- 监控队列信息:xinfo stream mq
- 监控组信息:xinfo groups mq
- 监控消费组成员信息:xinfo consumers mq mqGroup
相关问题
使用场景
- 通信
- 大数据分析
- 异地数据备份
消息ID的设计是否考虑了时间回拨的问题
XADD生成的1553439850328-0,就是Redis生成的消息ID,由两部分组成:时间戳-序号。时间戳是毫秒级单位,是生成消息的Redis服务器时间,它是个64位整型(int64)。序号是在这个毫秒时间点内的消息序号,它也是个64位整型
可以通过multi批处理,来验证序号的递增:
1 | 127.0.0.1:6379> MULTI |
由于一个redis命令的执行很快,所以可以看到在同一时间戳内,是通过序号递增来表示消息的。为了保证消息是有序的,因此Redis生成的ID是单调递增有序的。由于ID中包含时间戳部分,为了避免服务器时间错误而带来的问题(例如服务器时间延后了),Redis的每个Stream类型数据都维护一个latest_generated_id属性,用于记录最后一个消息的ID。若发现当前时间戳退后(小于latest_generated_id所记录的),则采用时间戳不变而序号递增的方案来作为新消息ID(这也是序号为什么使用int64的原因,保证有足够多的的序号),从而保证ID的单调递增性质。
消费者崩溃带来的会不会消息丢失问题
为了解决组内消息读取但处理期间消费者崩溃带来的消息丢失问题,STREAM 设计了 Pending 列表,用于记录读取但并未处理完毕的消息。命令XPENDIING 用来获消费组或消费内消费者的未处理完毕的消息
每个Pending的消息有4个属性:
- 消息ID
- 所属消费者
- IDLE,已读取时长
- delivery counter,消息被读取次数
当消费者下线后再次上线,可以读取该Pending列表,就可以继续处理该消息了,保证消息的有序和不丢失。
消息转移
消息转移即:消费者彻底宕机后转移给其它消费者处理,需要转移的有两个,一个是未消费的消息转移,一个是将宕机的消费者的 Pending消息转移。
在redis中,可使用 XCLAIM 命令,指定组、消费者、消息 ID 以及 IDLE(以被读取时长,只有超过这个时长,才能被转移),然后就可将这些消息转移到新的消费者的Pending列表中。
死信问题
如果某个消息,不能被消费者处理,也就是不能被XACK,这是要长时间处于Pending列表中,即使被反复的转移给各个消费者也是如此。此时该消息的delivery counter就会累加,当累加到某个我们预设的临界值时,我们就认为是坏消息(也叫死信,DeadLetter,无法投递的消息),由于有了判定条件,我们将坏消息处理掉即可,删除即可。删除一个消息,使用XDEL语法,演示如下:
1 | # 删除队列中的消息 |
对象机制
在redis中,为了完成对不同类型的键值进行不同的操作,所以redis必须让每个键都带有类型信息,使得程序可以检查键的类型,从而选择合适的处理方式。例如,redis在处理集合类型的时候,集合类型可以由字段和整数集合两种不同的数据结构实现,当用户执行ZADD命令时,无需用户关心集合的底层实现,由redis本身选择合适的方法进行处理。
即:操作苏剧类型的命令处理要对键的类型进行检查以外,还需要多根据类型的不同编码(不同的底层结构)进行多态处理。
redis为了实现上面的内容,构建了自己的类型系统,主要包括:
- redisObject对象
- 基于redisObject对象的类型检查
- 基于redisObject对象的显式多态函数
- 对redisObject进行分配、共享和销毁的机制
参考链接:https://redisbook.readthedocs.io/en/latest/datatype/object.html
redisObject
redisObject 是 Redis 类型系统的核心, 数据库中的每个键、值,以及 Redis 本身处理的参数, 都表示为这种数据类型。
在redis6.0中,redisObject的应用如下:
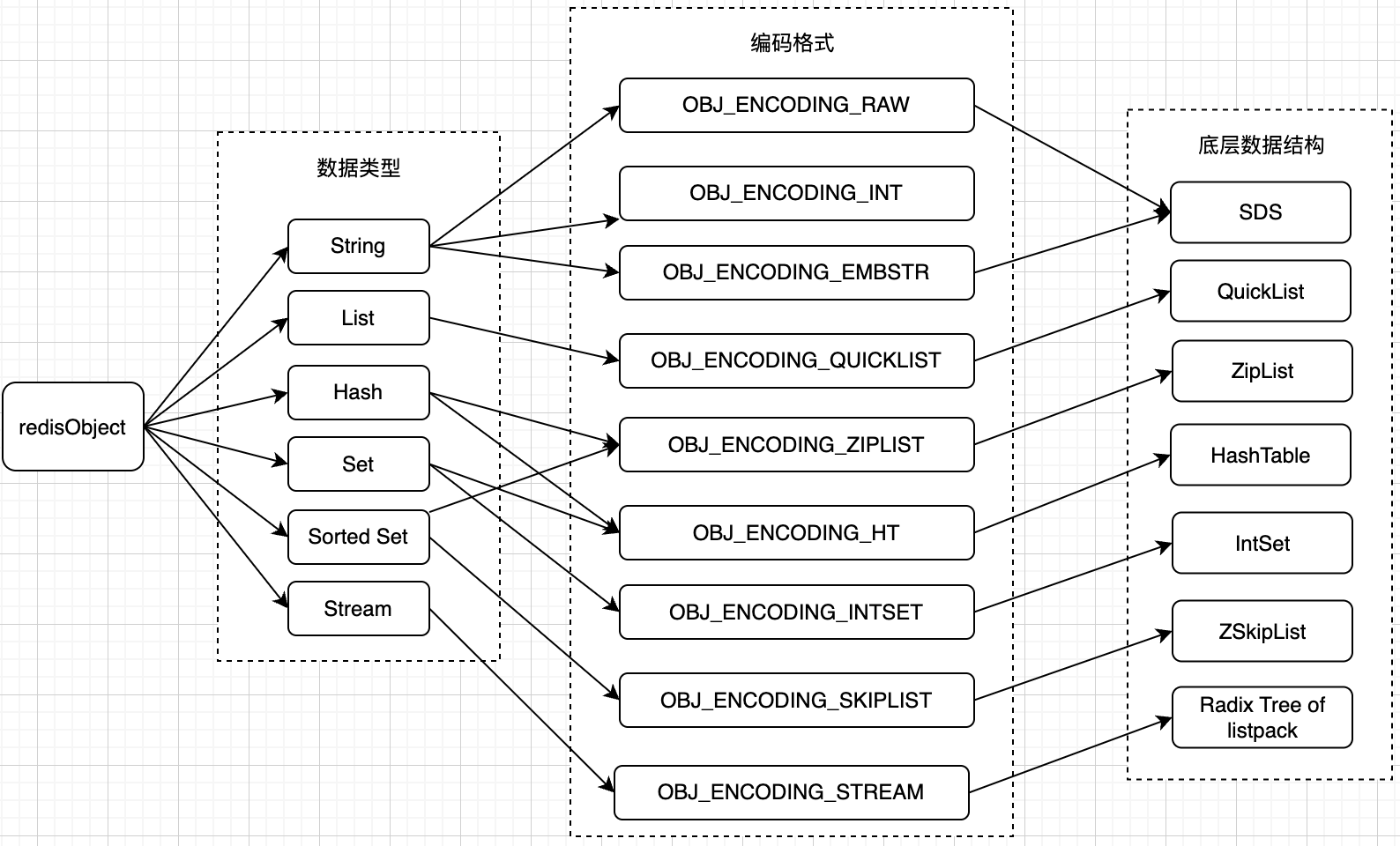
从上图可以看出,redis没中对象都是由redisObject与对应编码的数据结构组合而成,而没中对象类型对应若干编码方式,不同的编码凡事所对应的底层数据结构也不同。
在redis中,redisObject的结构为:
1 | typedef struct redisObject { |
type 、 encoding 和 ptr 是最重要的三个属性。
type 记录了对象所保存的值的类型,它的值可能是以下常量的其中一个:
1 | #define REDIS_STRING 0 // 字符串 |
encoding 记录了对象所保存的值的编码,它的值可能是以下常量的其中一个:
1 | #define REDIS_ENCODING_RAW 0 // 编码为字符串 |
ptr 是一个指针,指向实际保存值的数据结构,这个数据结构由 type 属性和 encoding 属性决定。
lru记录了对象最后一次被命令程序访问的时间。如果服务器开启了maxmemory选项,并且服务器用于回收的算法为volatile-lru或者allkeys-lru,那么当服务器占用的内存数超过了maxmemory选项所设置的上限值时,空转时长较高的那部分键会优先被服务器释放,从而回收内存。
对象共享
redis一般会把一些常见的值放到一个共享对象中,这样可使程序避免了重复分配的麻烦,也节约了一些CPU时间。
redis预分配的值对象如下:
- 各种命令的返回值,比如成功时返回的OK,错误时返回的ERROR,命令入队事务时返回的QUEUE,等等
- 包括0 在内,小于REDIS_SHARED_INTEGERS的所有整数(REDIS_SHARED_INTEGERS的默认值是10000

共享对象只能被字典和双向链表这类能带有指针的数据结构使用。像整数集合和压缩列表这些只能保存字符串、整数等自勉之的内存数据结构
对象淘汰
在redisObject中存在refcount属性,是对象的引用基数,如果显示为 0 则代表此对象是可以回收的。
- 每个redisObject结构都带有一个refcount属性,指示这个对象被引用了多少次;
- 当新创建一个对象时,它的refcount属性被设置为1;
- 当对一个对象进行共享时,redis将这个对象的refcount加一;
- 当使用完一个对象后,或者消除对一个对象的引用之后,程序将对象的refcount减一;
- 当对象的refcount降至0 时,这个RedisObject结构,以及它引用的数据结构的内存都会被释放。
底层数据结构
在上文中提到,redis的底层数据结构主要有:SDS 简单动态字符串、QuickList 快表、ZipList 压缩列表、HasTable 哈希表、InSet 整数集、ZSkipList 跳表。
详细的说明参考:https://pdai.tech/md/db/nosql-redis/db-redis-x-redis-ds.html